

斯坦福 AI 团队,竟然曝出了抄袭事件,而且抄袭的还是中国国产的大模型成果 —— 模型结构和代码,几乎一模一样!跟任何抄袭事故一样……AI 圈内都惊呆了。
斯坦福的这项研究叫做 Llama3-V,是于 5 月 29 日新鲜发布,宣称只需要 500 美元就能训出一个 SOTA 多模态大模型,比 GPT-4V、Gemini Ultra、Claude Opus 都强。

Llama3-V 的 3 位作者或许是拥有名校头衔加持,又有特斯拉、SpaceX 的大厂相关背景,这个项目短短几天就受到了不小的关注。
甚至一度冲上了 HuggingFace 趋势榜首页:
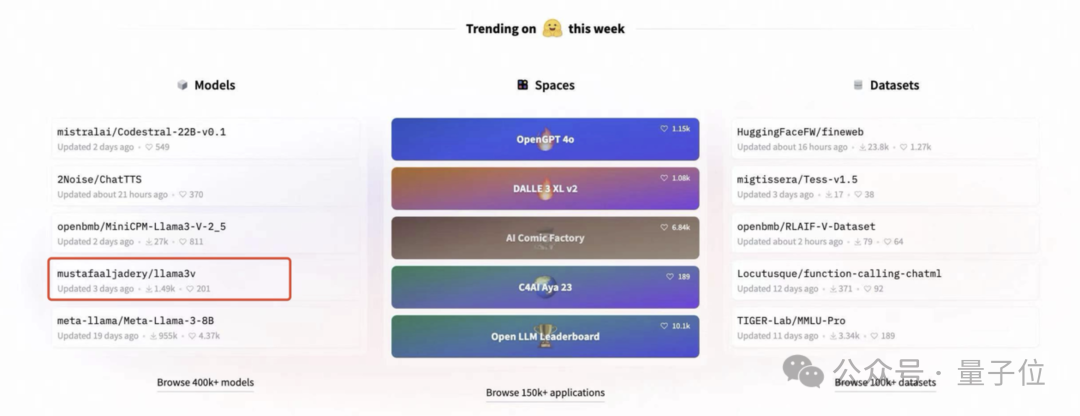
然而,戏剧性的一幕开始上演了。
有位细心的网友发现,咦?这“配方”怎么如此的熟悉?
然后他定睛一看,好家伙,这不就是 MiniCPM-Llama3-V 2.5(出自清华系明星创业公司面壁智能)嘛。
于是这位网友便跑到面壁智能 GitHub 项目下开始爆料了:
你们家大模型被斯坦福团队抄袭了!
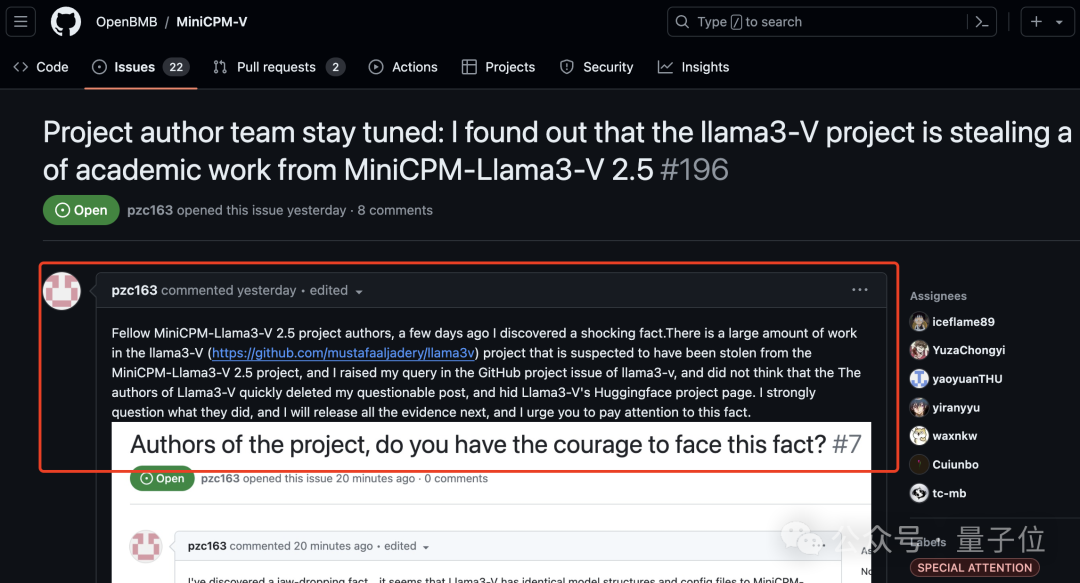
并且他还附上了一堆的证据,最直接的莫过于这张 2 个模型代码的对比图了:
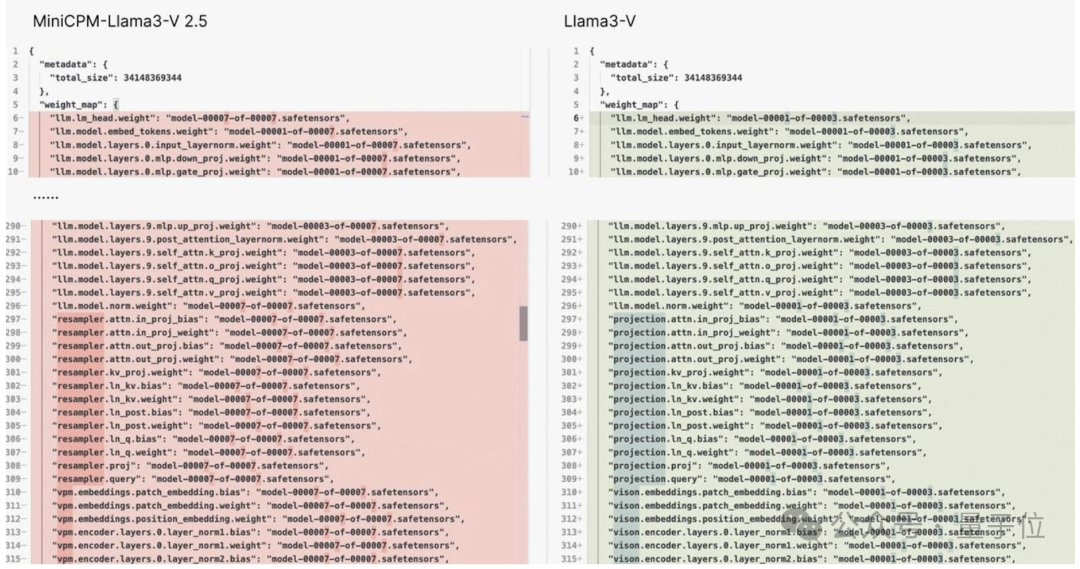
Emmm…… 用这位网友的话来说就是:
模型结构、代码、配置文件,简直一模一样,只是变量名变了而已。
至于为什么这位网友要跑到面壁智能 GitHub 项目下面留言,是因为他之前已经给 Llama3-V 作者留过言了,但斯坦福团队的做法竟是删库跑路……
没错,现在不论是 GitHub 还是 HuggingFace,统统都是 404:
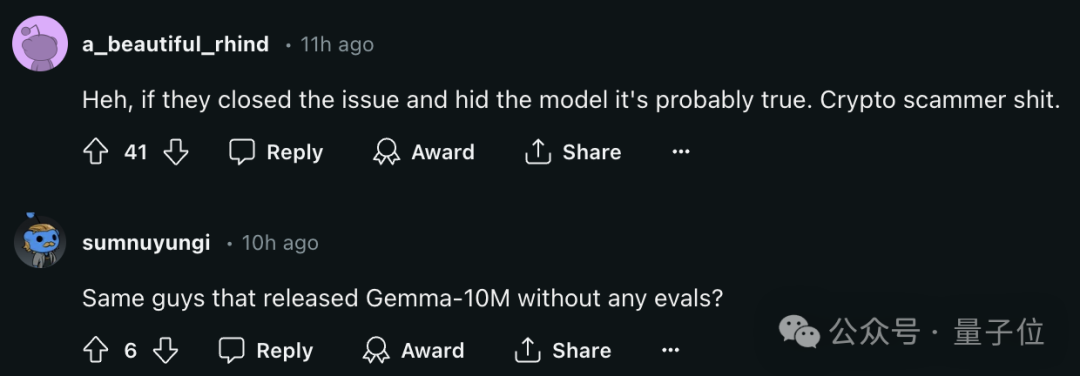
并且这事现在还在持续发酵的过程中,网上吃瓜的群众也是越来越多。
那么我先来一同回顾一下这件 drama 事情的始末。
“代码和架构一模一样”
正如刚才所述,一个网友爆料 Llama3-V 抄袭 MiniCPM-Llama3-V 2.5,跑到面壁智能的 GitHub 主页提醒团队注意,并把关键证据都一一截图列举整理了下来,这才有了整个抄袭门的还原现场。
以下是来自这位网友的证据。
证据一,Llama3-V 的模型架构和代码与 MiniCPM-Llama3-V 2.5 几乎完全相同:
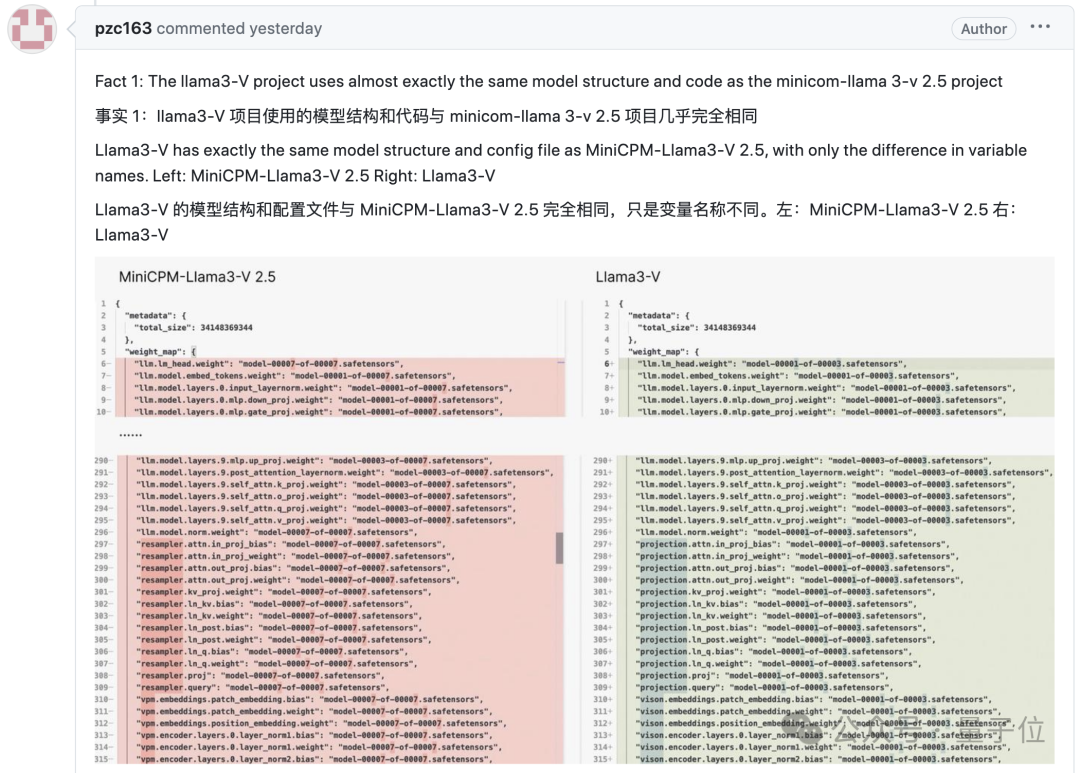
看下面的例子,配置文件就改了图像切片、分词器、重采样器和数据加载等格式化和变量名:
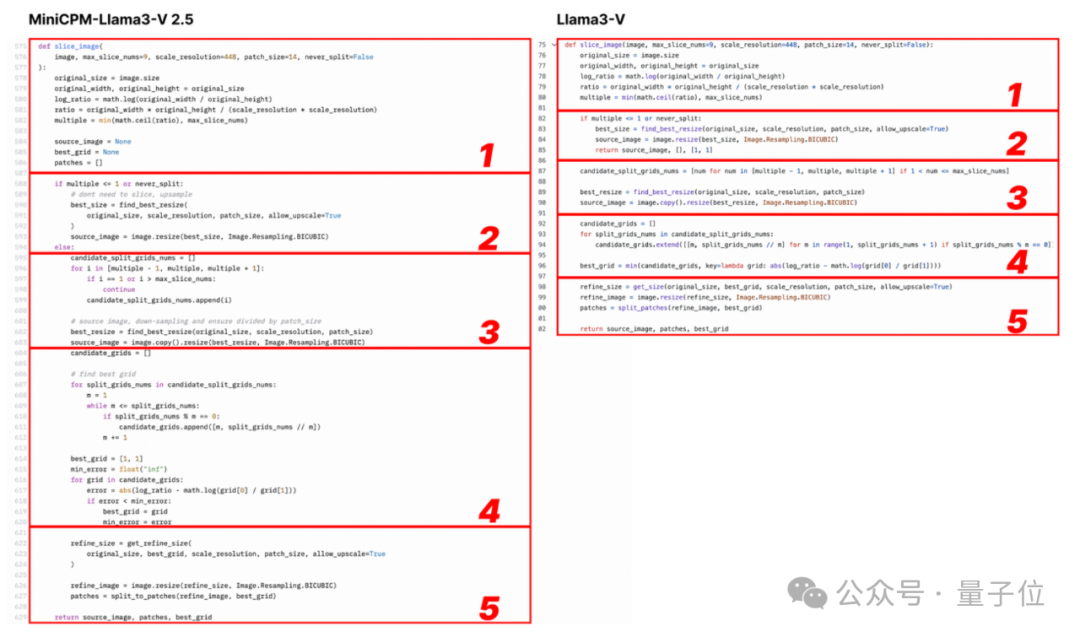
Llama3-V 作者表示参考了 LLaVA-UHD 架构,在 ViT 和 LLM 等选择上有一些差异。但实际上,网友发现他们的具体实现在空间模式等很多方面都与 LLaVA-UHD 不同,却出奇与 MiniCPM-Llama3-V 2.5 一致。
甚至,Llama3-V 还用了 MiniCPM-Llama3-V 2.5 的分词器,连 MiniCPM-Llama3-V 2.5 定义的特殊符号都能“巧合”实属离谱。

证据二,网友质疑 Llama3-V 作者是如何在 MinicPM-Llama3-V2.5 项目发布之前就使用上 MinicPM-Llama3-V2.5 分词器的。
Llama3-V 作者给的回复是这样婶儿的,说是用的面壁智能上一代 MinicPM-V-2 项目的:
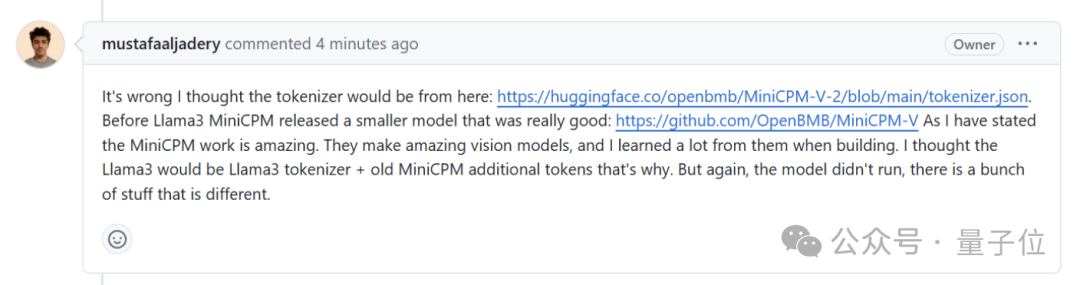
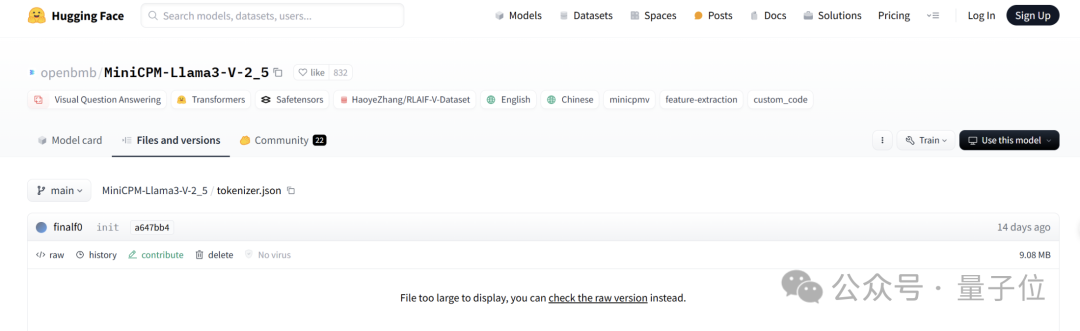
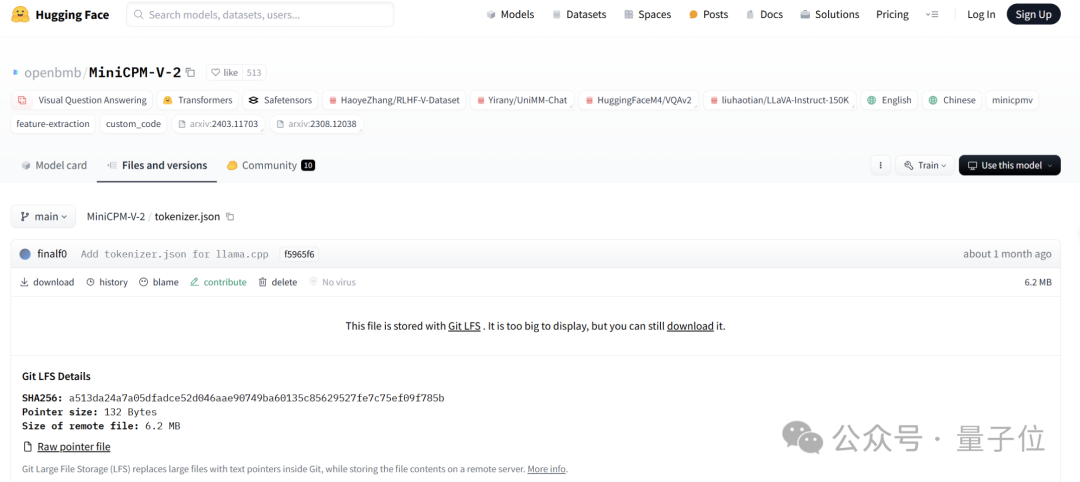
但事实却是,HuggingFace 中,MiniCPM-V2 与 MiniCPM-Llama3-V 2.5 分词器分别是两个文件,文件大小也完全不同。
MiniCPM-Llama3-V 2.5 的分词器是用 Llama3 分词器加上 MiniCPM-V 系列模型的特殊 token 组成,而 MiniCPM-V2 的发布都在 Llama3 开源之前,怎么会有 Llama3 分词器。
证据三,Llama3-V 作者随后无故删除了网友在 Llama3-V 页面上提交的质疑他们抄袭的问题。
而且,他们似乎对 MiniCPM-Llama3-V 2.5 架构或他们自己的代码都不完全了解。
感知器重采样器(Perceiver resampler)是单层交叉注意力,而不是双层自注意力。但是下图所示 Llama3-V 的技术博客里作者的理解很明显是错的。

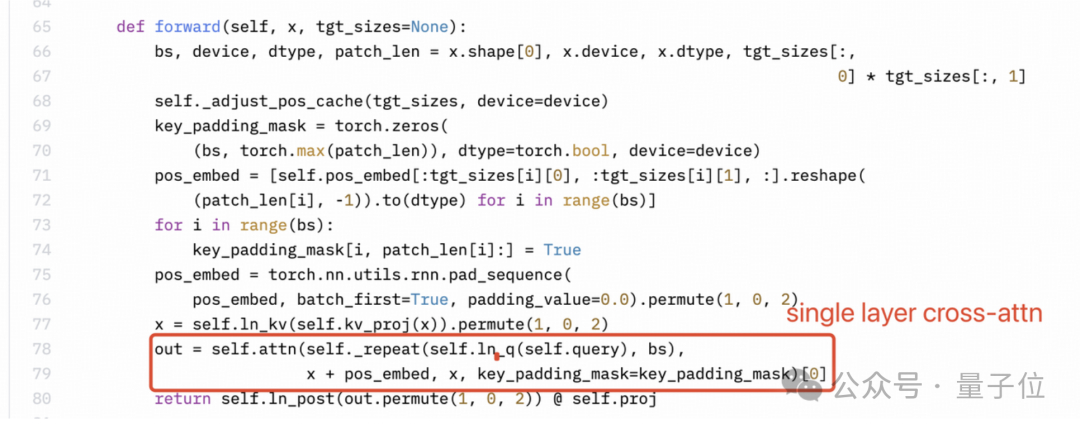
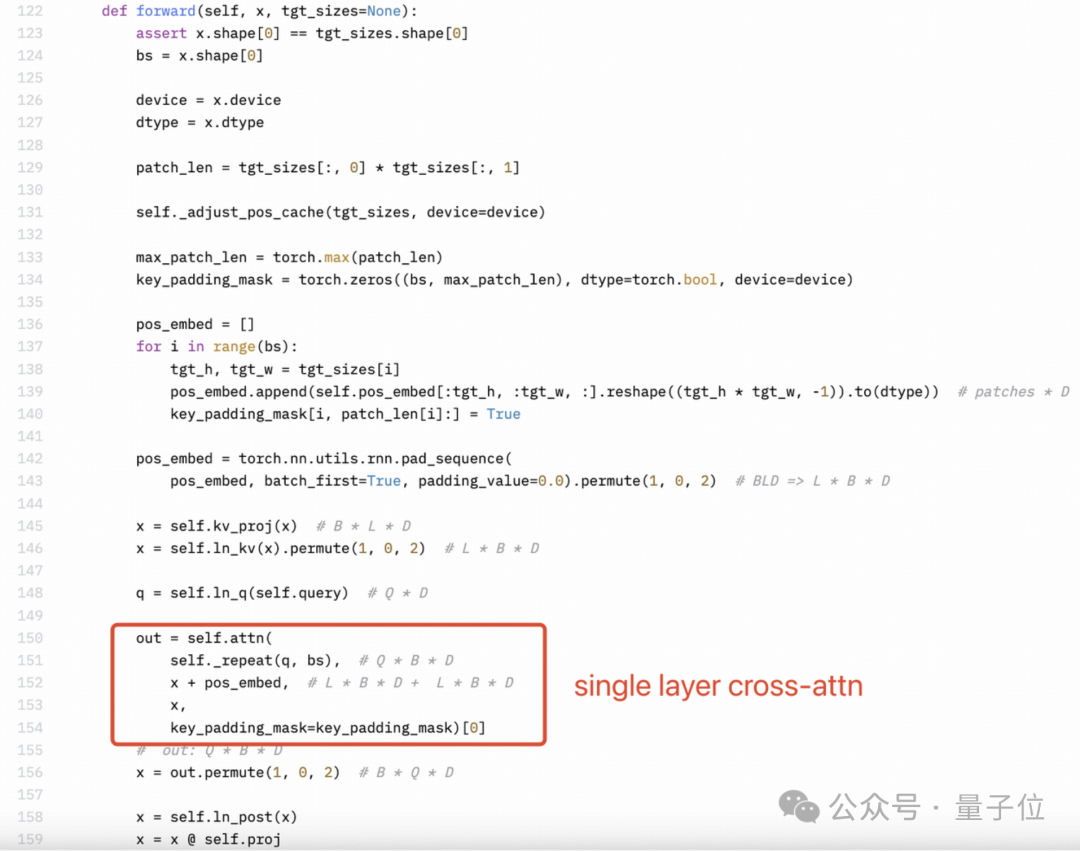
SigLIP 的 Sigmoid 激活也不用于训练多模态大语言模型,而仅用于预训练 SigLIP。
视觉特征提取不需要 Sigmoid 激活:

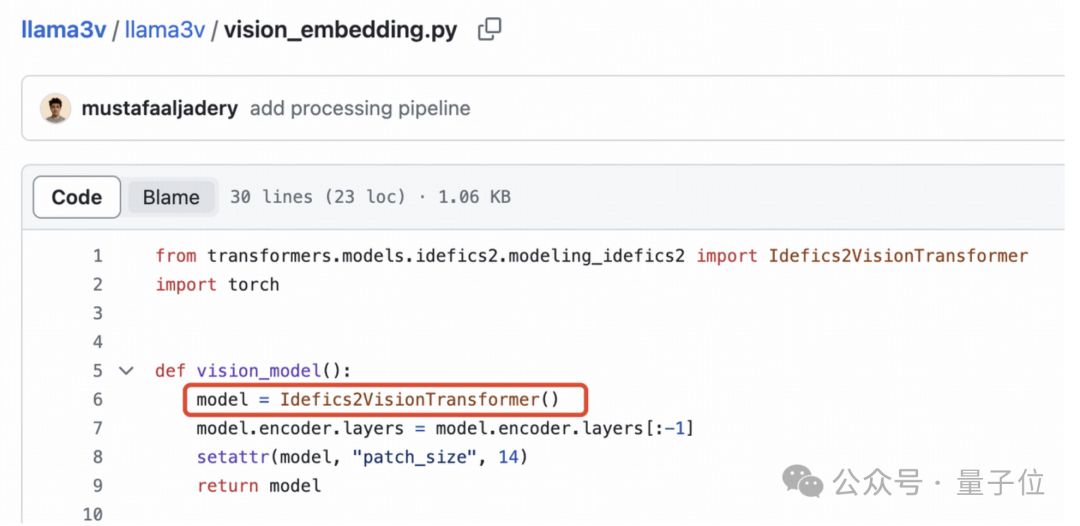
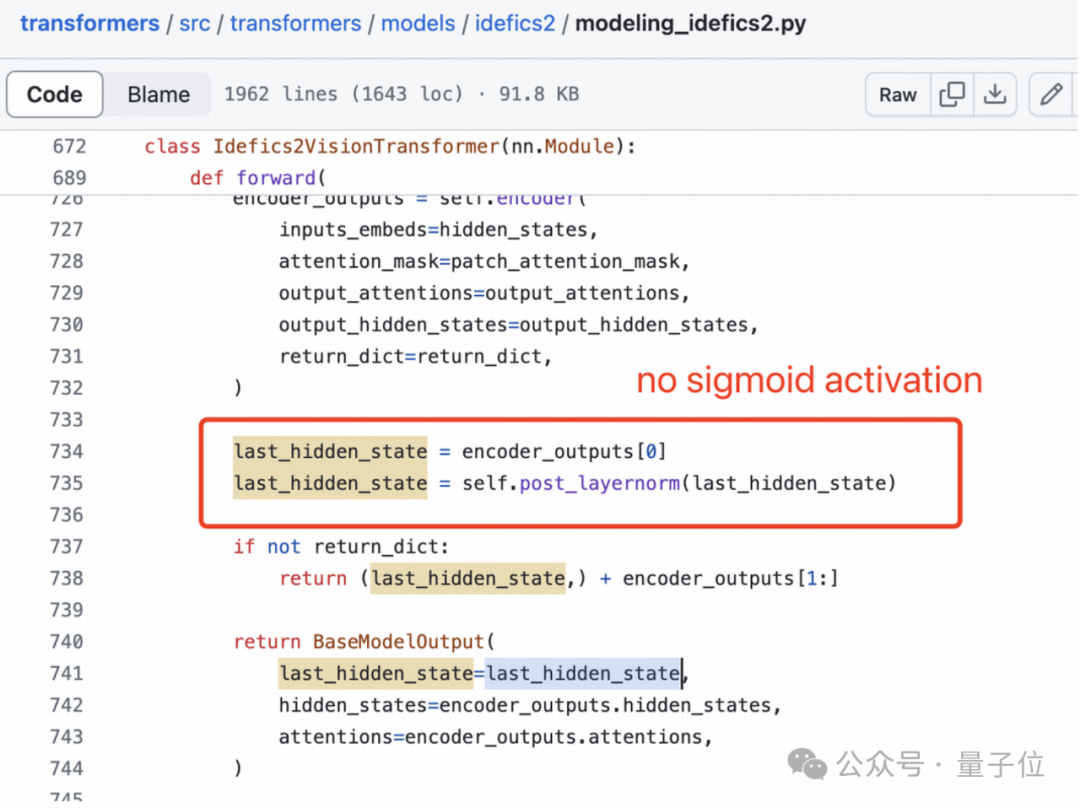
基于以上三点事实,这位网友认为足以证据证明 Llama3-V 项目窃取了 MiniCPM-Llama3-V 2.5 项目的学术成果。
但还没完,他随后又补充了两点证据。
几天前,当这位网友尝试运行 Llama3-V 时,发现他们提供的代码无法与 HuggingFace 的 checkpoint 一起使用,反馈问题没有得到作者回复。
于是网友把从 HuggingFace 下载的 Llama3-V 模型权重中的变量名改成了 MiniCPM-Llama3-V 2.5 的,惊奇发现模型居然可以用 MiniCPM-V 代码成功运行。
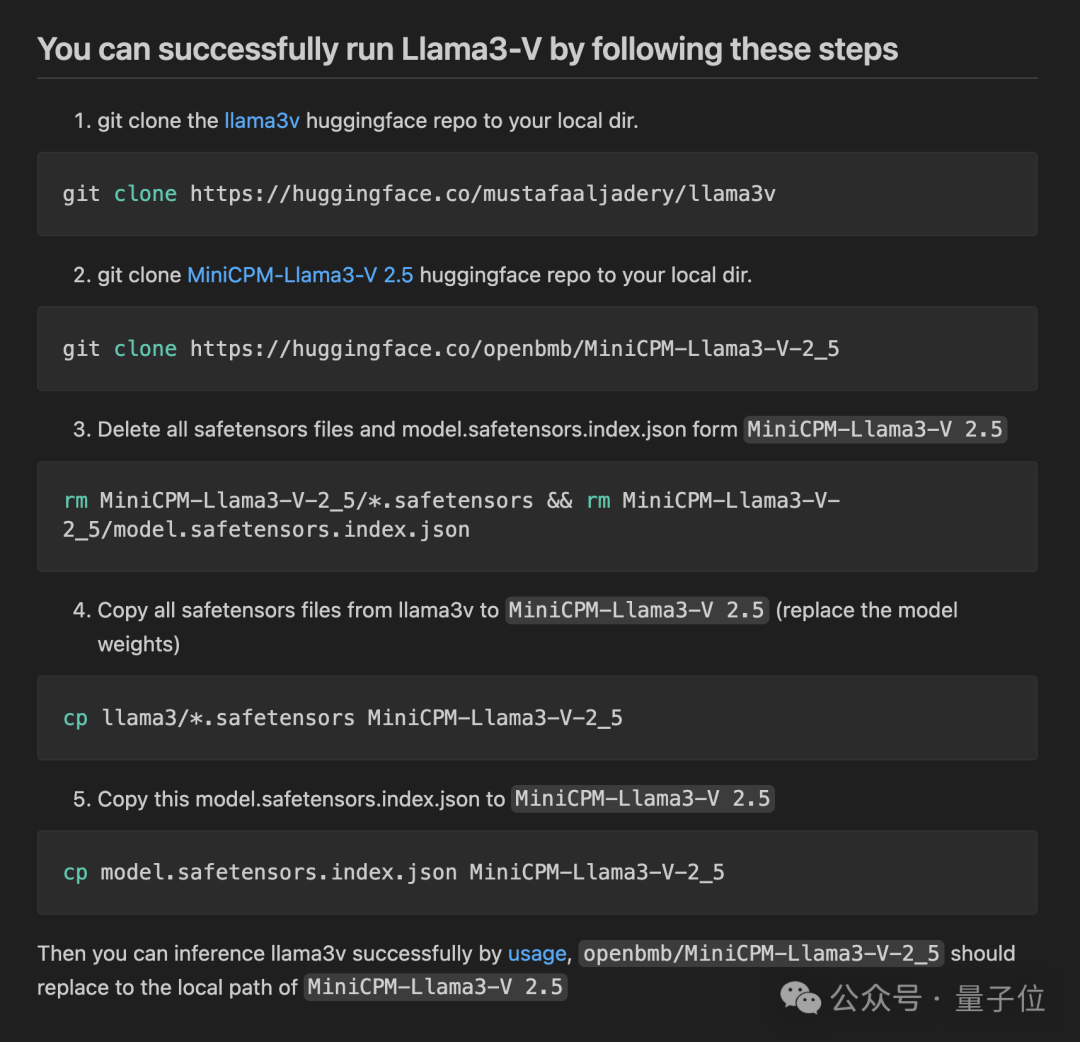
此外,如果将高斯噪声(由单个标量参数化)添加到 MiniCPM-Llama3-V 2.5 的 checkpoint,结果就是会得到一个行为与 Llama3-V 极其相似的模型。
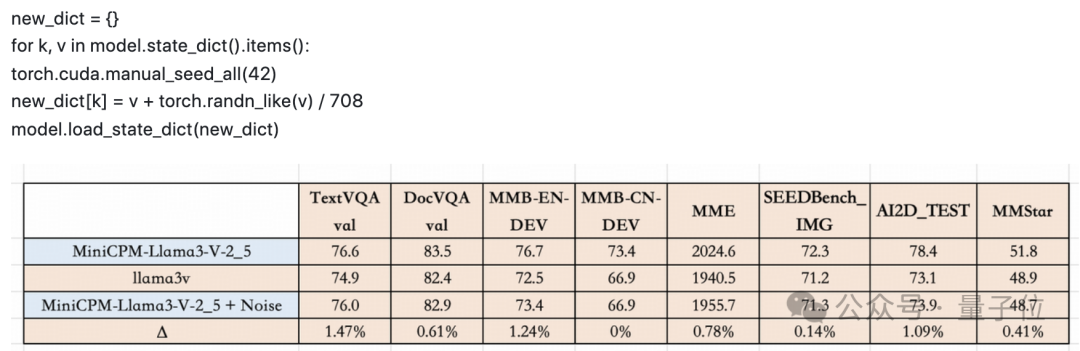
收到网友的提醒后,MiniCPM-Llama3-V 2.5 团队这边也迅速展开了调查,他们按照网友的在 GitHub 上的说明,使用 Llama3-V 的 checkpoint 和 MiniCPM-Llama3-V 2.5 的代码和配置文件正确获取了推理结果。
于是,一个更为关键性的证据出现了。
Llama3-V 在一些未公开的实验性特征上表现出与 MiniCPM-Llama3-V 2.5 高度相似的行为,而这些特征是根据 MiniCPM-Llama3-V 2.5 团队内部数据训练的。
例如,识别清华简!
MiniCPM-Llama3-V 2.5 特有的功能之一是识别清华简,这是一种非常罕见、于战国时期写在竹子上的中国古代文字。
训练图像是从最近出土的文物中扫描出来的,由 MiniCPM-Llama3-V 2.5 团队进行了标注,尚未公开发布。
而 Llama3-V 的识别情况和 MiniCPM-Llama3-V 2.5 极为相似。
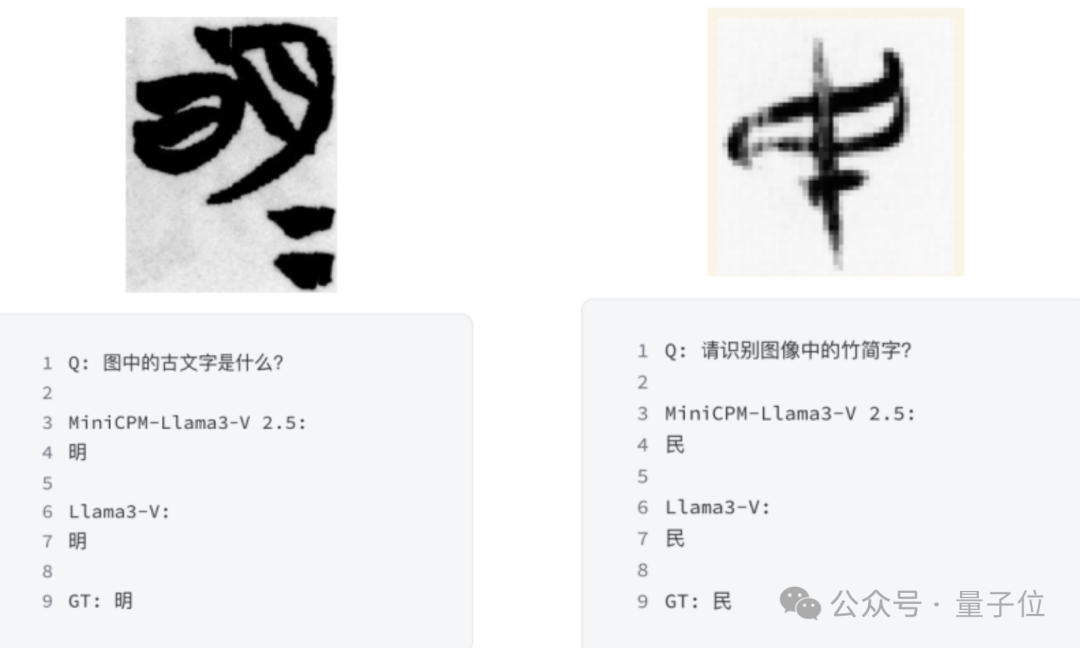
识别错误的情况竟也出奇一致:

MiniCPM-Llama3-V 2.5 团队还在 1000 张竹简图像上测试了几种基于 Llama3 的视觉-语言模型,并比较了每对模型的预测精确匹配。
结果,每两个模型之间的重叠为零,而 Llama3-V 和 MiniCPM-Llama3-V 2.5 之间的 && 重叠达到了惊人的 87%**。
此外,MiniCPM-Llama3-V 2.5 和 Llama3-V 甚至具有相似的错误分布。Llama3-V 和 MiniCPM-Llama3-V 2.5 分别做出 236 和 194 个错误预测,重叠部分为 182 个。
且按照网友在 GitHub 上的指令获得的 MiniCPM-Llama3-V2.5-noisy 显示出与 Llama3-V 几乎相同的定量结果,真令人匪夷所思……
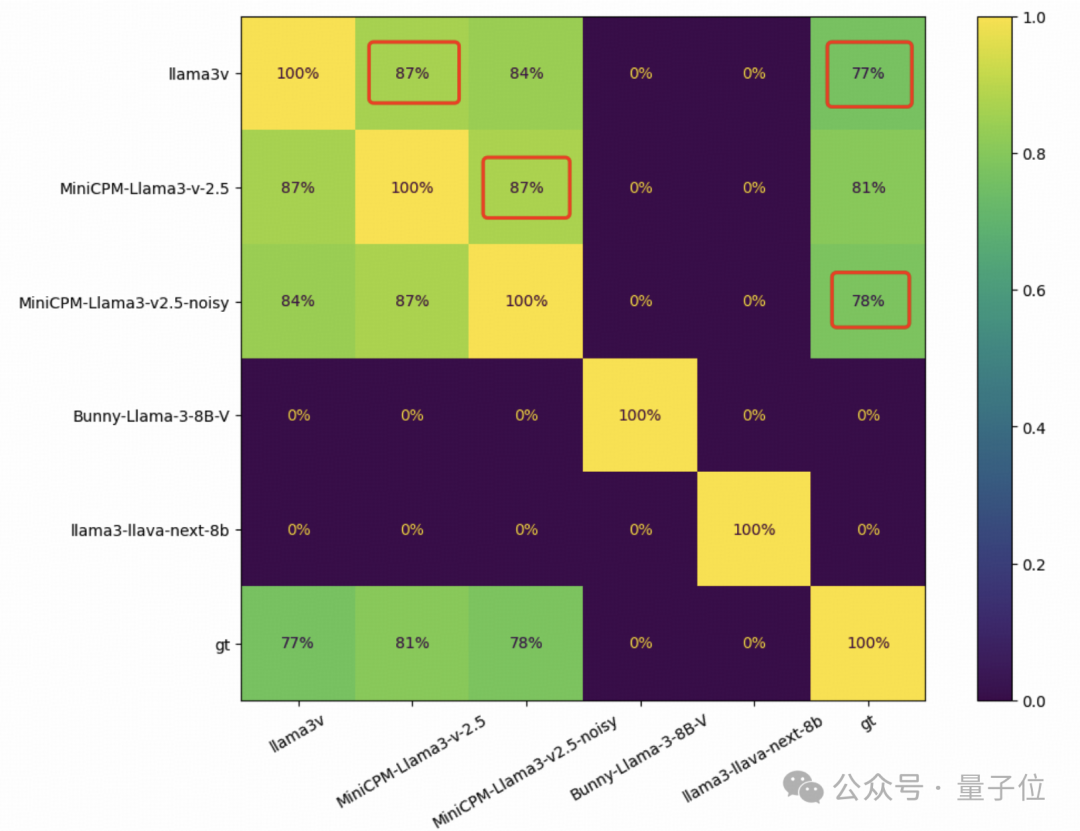
在另一个 MiniCPM-Llama3-V 2.5 内部数据上训练的未公开功能 ——WebAgent 上,也出现了同样的情况。
Llama3-V 甚至和 MiniCPM-Llama3-V 2.5 团队新定义的 WebAgent 模式中犯的错误都一样。
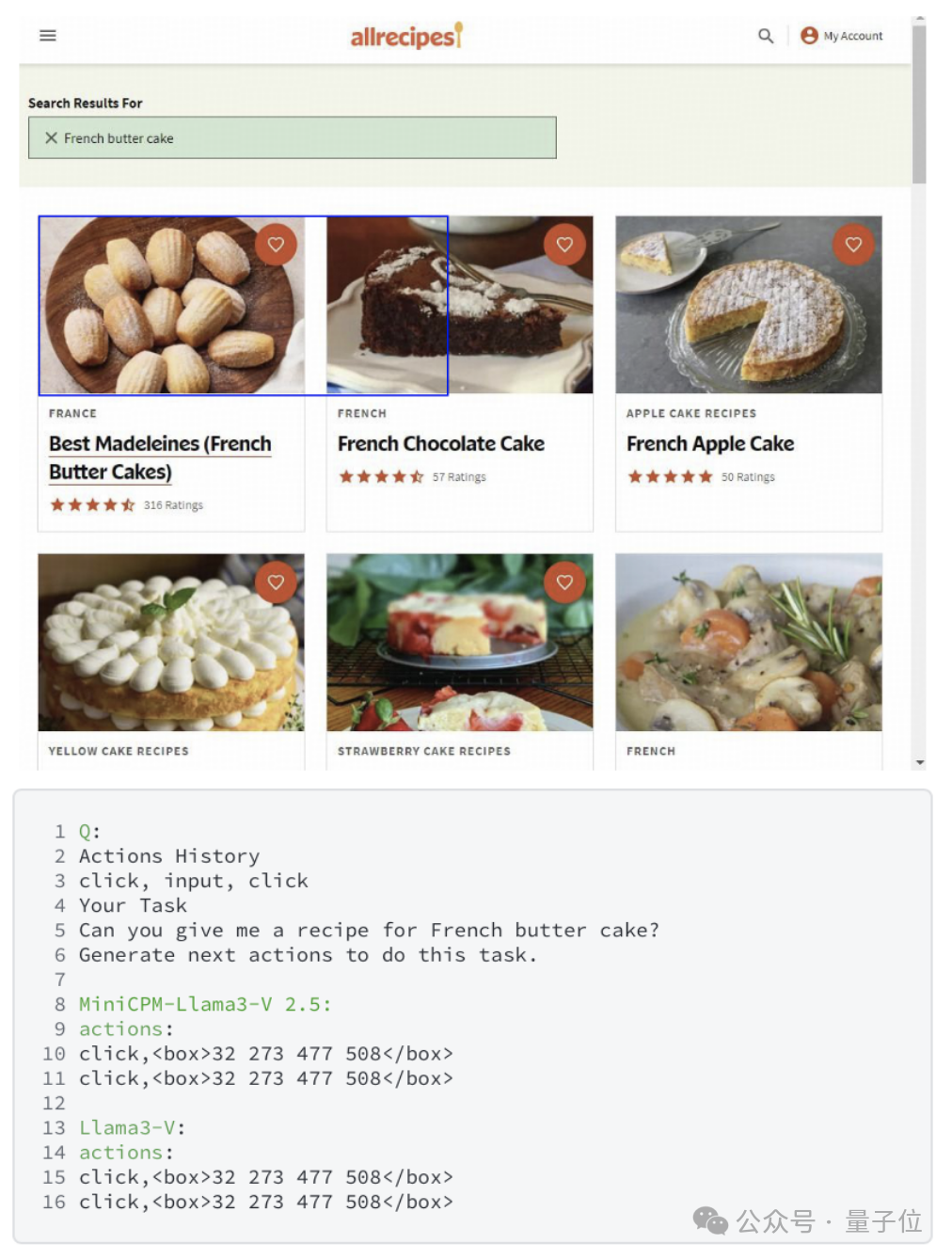
鉴于这些结果,MiniCPM-Llama3-V 2.5 团队表示很难将这种不寻常的相似性解释为巧合,希望 Llama3-V 作者能对这个问题给出一个正式的解释。

斯坦福团队已删库跑路
虽然斯坦福的 2 位本科生已经下架了几乎所有与之相关的项目,但其实在此之前,他们最初在面对质疑的时候还是做出了些许的解释。
例如他们强调,Llama3-V 这项工作的时间是要早于面壁智能的 MiniCPM,只是使用了他们的 tokenizer。
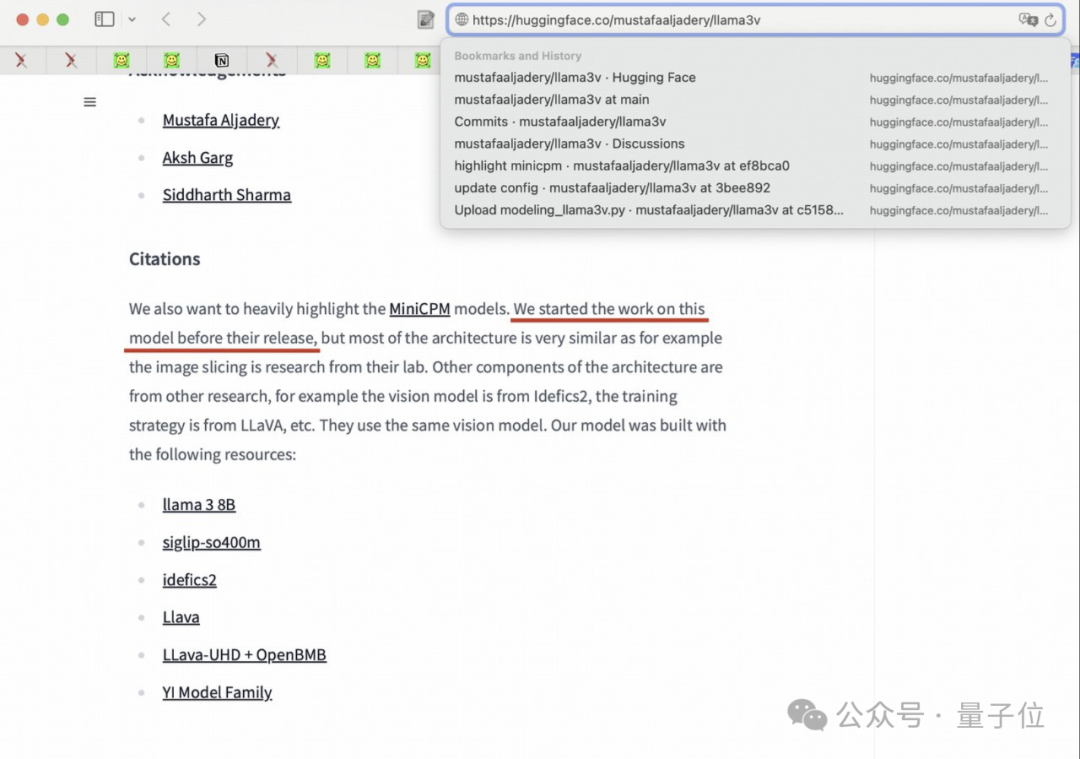
不过作者对 Medium 上的声明还是做了保留:
非常感谢那些在评论中指出与之前研究相似之处的人。
我们意识到我们的架构非常类似于 OpenBMB 的“MiniCPM-Llama3-V 2.5,他们在实现上比我们抢先一步。
我们已经删除了关于作者的原始模型。
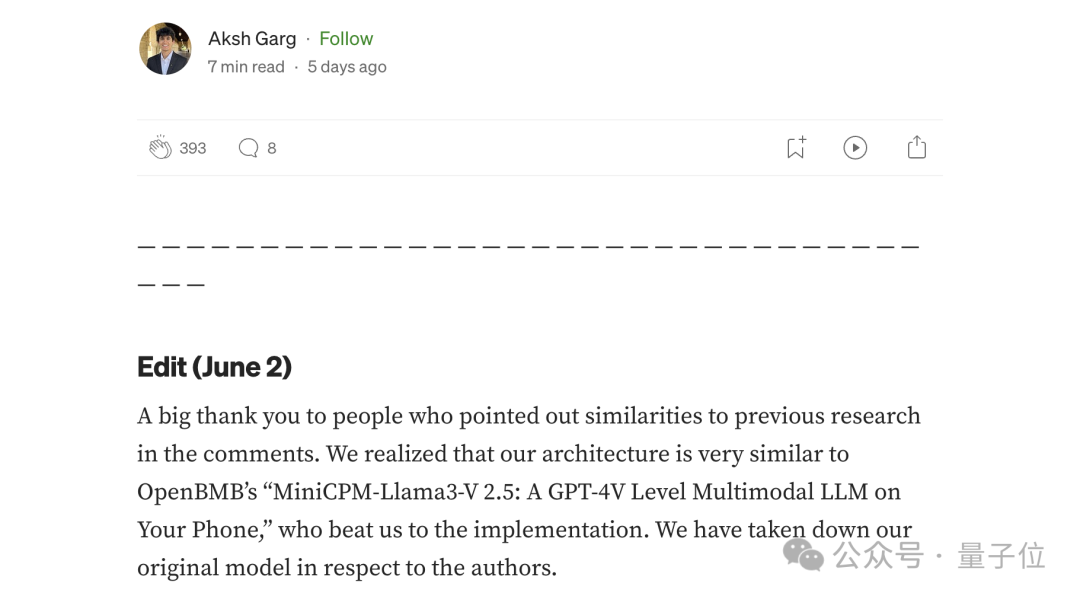
对此,一部分网友表示,既然选择删掉项目,那么就表示确实存在一定的问题。
不过另一方面,对于抄袭这事也有不一样的声音 ——
MiniCPM-Llama3-V 2.5 不也是在 Llama3 的基础上做的改良吗?不过连 tokenizer 都直接拿来用就应该不算是借鉴了。
而就在刚刚,另一个戏剧性的事情发生了。
斯坦福的作者在中午时间做出了最新的回应:
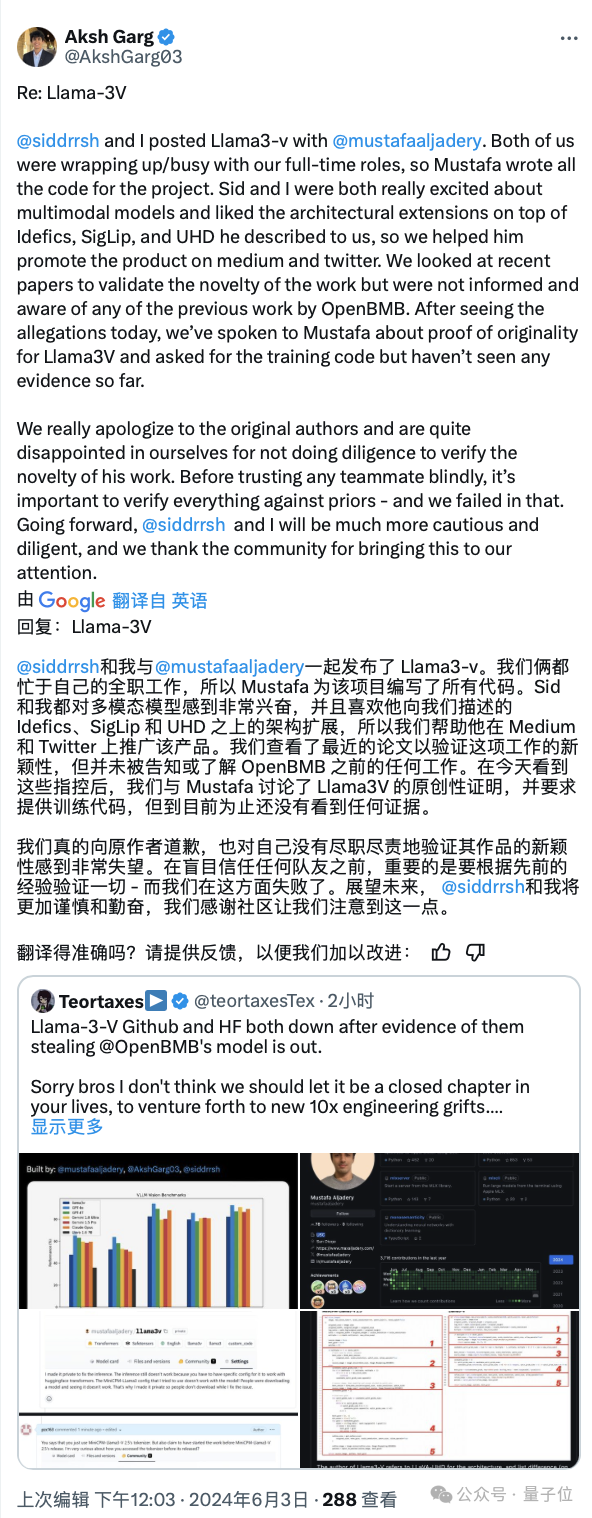
但现在…… 这条回应又删掉了。
而面壁智能这边,CEO 李大海也做出了正式回应:


参考链接:
[1]https://github.com/OpenBMB/MiniCPM-V/issues/196
[2]https://github.com/mustafaaljadery/Llama3-V
[3]https://www.reddit.com/r/LocalLLaMA/comments/1d6f1f3/Llama3-V_project_is_stealing_a_lot_of_academic/
[4]https://www.reddit.com/r/LocalLLaMA/comments/1d6f1f3/Llama3-V_project_is_stealing_a_lot_of_academic/?rdt=41696&onetap_auto=true&one_tap=true
[5]https://aksh-garg.medium.com/llama-3v-building-an-open-source-gpt-4v-competitor-in-under-500-7dd8f1f6c9ee
本文来自微信公众号:量子位 (ID:QbitAI),作者:金磊 西风